
Predictor de precios de mercado - General Motors - Parte III
Como hemos comentado en los posts anteriores, en este set de diferentes notebooks trataremos de hacer un análisis de la serie temporal de los precios de cierre de mercado de la compañía General Motors en la bolsa de NY. Como objetivo se fijará crear un modelo de referencia y tratar de mejorarlo usando redes secuenciales. El objeto de estudio de hoy es:
El último punto, Modelos secuenciales intentaremos crear modelos de redes secuenciales que mejoren estos modelos de referencia.
Forecast: Redes secuenciales¶
Una vez definido nuestro modelos de referencia como ARIMA, vamos a intentar crear modelos de redes secuenciales que lo mejoren. Alcanzado este punto se incorporarán indicadores técnicos que mejorarán aún más esta predicción.
En el post de hoy trataremos:
1.- Modelo RNN
2.- Modelos LTSM
3.- Resultados Finales y conclusiones
Modelo RNN (simple)¶
Cargar dataset ya creado¶
Una vez teniendo creado el dataset, podemos importarlo directamente desde el directorio.
symbol = 'GM'
serie = pd.read_csv(file_data_GM)
serie.index = serie.pop('date')
serie.index = pd.to_datetime(serie.index)
serie.head()
data = serie['4. close'].values
print(data)
Cálculo de algunos indicadores¶
#Media movil
from alpha_vantage.techindicators import TechIndicators
symbol='NYSE:GM'
ti = TechIndicators(key=API_KEY,output_format='pandas')
#Obtenemos la media movil mensual.
data_macd, meta_macd = ti.get_macd(symbol=symbol, interval='daily',series_type='close')
serie = pd.merge(serie, data_macd,on='date')
serie.head()
data = serie.loc[:,['4. close', 'MACD']].values
print(data)
El primer paso para el RNN es preparar los datos en n bloques con ventandas separadas por una un desplazamiento que va a ser igual a 1, generando un cubo de datos en el que las filas serían cada entrada a la red, las columnas el instante t-n y las dimesiones el número de variables independientes a la entrada.
Si sólo tomamos el precio de días anteriores. el número de variables independientes es 1. Este valor crecerá unitariamente con el número de variables exógenas que añadamos.
#split a sequence into samples
def split_sequence(sequence, n_steps):
X = list()
Y = list()
for i in range(len(sequence)):
# find the end of this pattern
end_ix = i + n_steps
# check if we are beyond the sequence
if end_ix > len(sequence)-1:
break
# gather input and output parts of the pattern
seq_x = sequence[i:end_ix-1,:]
seq_y = sequence[end_ix,0:1]
X.append(seq_x)
Y.append(seq_y)
return (np.array(X), np.array(Y))
Modelado¶
Redes Neuronales Recurrentes¶
Para el modelado de redes neuronales, hemos escogido arquitecturas recurrentes, adaptadas para tipos de datos secuenciales. Como ya sabemos, en el caso de una serie temporal, cada input de la secuencial depende del o de los anteriores. Las redes neuronales recurrentes (RNN) siguen el mismo principio que el perceptrón multicapa, pero cada nuevo input de la secuencia se retroalimenta también con la salida del los inputs anteriores, como podemos ver a continuación:
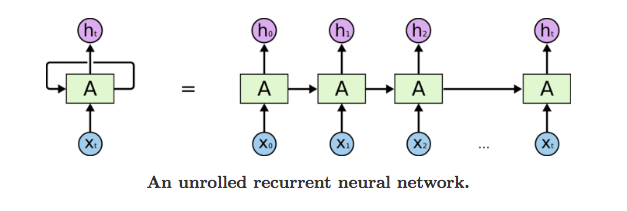
Esta retroalimentación hace el efecto de "memoria" y captura información en base a la información calculada a lo largo de la secuencia. En este caso, el problema se somete a una entrada de secuencias de precios con respecto al tiempo y queremos predecir el siguiente valor, por ello, emplearemos un modelo many-to-one.

En las RNN simples pueden surgir dos problemas a la hora de intentar ajustar un modelo:
Vanishing Gradient: surge cuando intentamos propagar el error hacia atrás y las derivadas parciales comienzan a dar resultados cada vez más y más pequeños. Esto desencadena que la contribución de los steps iniciales sea practicamente nula en el proceso del descenso por gradiente. Esto provoca que cuando las secuencias son muy largas, se pierdan las dependencias a largo plazo. Esto puede mitigarse empleando funciones de activación distintas (Relu) o diferentes tipos de celdas recurrentes como son LSTM (Long Short Term Memory) o GRU (Gated Recurrent Unit).
Exploding Gradient. Esto surge cuando cuando el algoritmo asigna importancias excesívamente grandes a los pesos. Este problema puede mitigarse aplicando gradient clip o empleando algoritmos de optimización que ajusten la tasa de aprendizaje de manera más eficiente como RMSprop o Adam.
Definición del modelo¶
Para el modelo, consideramos la regularización L2, que saca una salida no-sparse, interesante en nuestro caso:
num_steps = split_steps - 1
num_var = x_train_data.shape[2]
output_size = y_train_data.shape[1]
import keras.backend as K
def rmse (y_true, y_pred):
return K.sqrt(K.mean(K.square(y_pred -y_true), axis=-1))
from keras.models import Sequential
from keras.layers import Dense, Activation, LSTM, Dropout, SimpleRNN
from keras.optimizers import SGD
from keras.regularizers import l2
from keras.callbacks import EarlyStopping
model = Sequential()
model.add(SimpleRNN(50,
activation='relu',
kernel_regularizer=l2(0.001),
return_sequences=True))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(SimpleRNN(50,
activation='relu',
kernel_regularizer=l2(0.001),
return_sequences=True))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(SimpleRNN(50,
activation='relu',
kernel_regularizer=l2(0.001)))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(output_size,
activation='linear',
kernel_regularizer=l2(0.001)))
model.compile(optimizer='adam', loss='mse', metrics=['mse',rmse,'mae','mape'])
Entrenamiento¶
Para entrenar, utilizamos la técnica conocida como Early Stopping, lo cual permite "cortar" el entreanmiento para prevenir el over-fitting.
Utilizamos además 50 épocas alimentándolo con batches de 32 secuencias:
es = EarlyStopping(monitor='val_loss', mode='min', patience=10, verbose=1)
print('RNN')
history_train = model.fit(x_train_data, y_train_data,
epochs=50,
batch_size=3,
shuffle=False,
validation_split=0.3,
callbacks=[es],
verbose=1)
plt.plot(history_train.history['mean_squared_error'])
plt.plot(history_train.history['mean_absolute_error'])
plt.plot(history_train.history['rmse'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['MSE','MAE','RMSE'], loc='upper left')
plt.show()
plt.plot(history_train.history['mean_absolute_percentage_error'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['MAPE'], loc='upper left')
plt.show()


Predicción¶
Las predicciones del modelo serán entonces:
- Dado una ventana de 5 días de precios y sus diferenciales de grado 1, obtener el valor del día siguiente. Obtendremos para cada cada secuencia de Test, la predicción del siguiente día y al almacenaremos los resultados.
- Una vez tenidos los resultados del modelo, calcularemos las métricas de error para evaluar su ajuste.
- Por último, graficaremos tanto los puntos de predicción como los valores reales para ver cómo se se comporta la red con valores que no han sido vistos antes y cómo se ajusta al patrón de la serie.
y_pred = model.predict(x_test_data, verbose=0)
Métricas¶
def mape(y_true, y_pred):
y_true_, y_pred_ = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true_ - y_pred_) / y_true_)) * 100
prd, ytr = np.squeeze(y_pred), np.squeeze(y_test_data)
mse = sk_mse(ytr, prd)
rmse = np.sqrt(sk_mse(ytr, prd))
mae = sk_mae(ytr, prd)
mape = mape(ytr, prd)
metrics_ = pd.DataFrame([mse,rmse,mae,mape], index=['mse','rmse','mae','mape'], columns=['Metrics'])
metrics_.loc['mape'] = metrics_.loc['mape'].map(lambda x: str(round(x, 2))+'%')
metrics_
Visualización de la predicción¶
Podemos ver que el modelo aprende el patrón que sigue la serie real, excepto en algunmos tramos donde ocurren valores anómalos (picos). Pero a grandes rasgos, consigue detectar cuándo la serie tiende a subir o a bajar su valor.
y_pred[:5], y_test_data[:5]
plt.plot(y_pred, c='seagreen', alpha=0.6)
plt.legend(['prediction'], loc='best')
plt.title('RNN')

plt.plot(y_test_data, c='orange', alpha=0.5)
plt.legend(['real'], loc='best')
plt.title('RNN')

Long Short Term Memory (LSTM)¶
Cargar dataset ya creado¶
Una vez teniendo creado el dataset, podemos importarlo directamente desde el directorio.
serie = pd.read_csv(file_data_GM)
serie.index = serie.pop('date')
serie.index = pd.to_datetime(serie.index)
serie.head()
serie.shape
Cálculo de algunos indicadores¶
Calculamos algunos indicadores como el MACD, la media móvil, etc. Por último, sabemos que la serie tiene fuertes indicios de ser de tipo random walk. Realizamos la diferenciación de grado 1 sobre la serie y lo agregamos como variable.
serie['26_ema'] = serie['4. close'].ewm(span=26, min_periods=0, adjust=True, ignore_na=False).mean()
serie['12_ema'] = serie['4. close'].ewm(span=12, min_periods=0, adjust=True, ignore_na=False).mean()
serie['MACD'] = serie['12_ema'] - serie['26_ema']
serie = serie.fillna(0)
serie.head()
daily = serie['4. close'].asfreq('D', method='pad')
mean_roll = daily.rolling(15).mean().fillna(0)
mean_roll.name = 'mavg'
std_roll = daily.rolling(15).std().fillna(0)
std_roll.name = 'mstd'
diff_1 = serie['4. close'].diff().dropna()
diff_1.name = 'diff_1'
serie = pd.concat([serie, mean_roll, std_roll, diff_1], axis=1).dropna()
serie.head()
Preparación del input¶
Para poder alimentar la red neuronal recurrente, el input debe estar formado por secuencias de N timesteps de ventana fija. El input puede ser univariable (solo se tiene en cuenta una variable para el análisis) o multivariable donde cada secuencia temporal será la combinación de dos o más variables, las cuales podrían ser indicadores o variables creadas a partir de la información de la serie, como la diferencición de la misma.
La selección de las variables que compondrán la secuencia así como el tamaño de la ventana es un parámetro que hay que ajustar en función de las características de la serie. Para el entrenamiento, seleccionamos los primeros 1553 steps, dejando 661 para realizar la evaluación del modelo.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence)-1:
break
seq = sequence[i:end_ix+1]
X.append(seq)
return np.array(X)
def train_test(data, test_size=0.2, scale=True):
if scale:
scaler = MinMaxScaler(feature_range=(0,1))
data2 = scaler.fit_transform(data)
else:
data2 = np.copy(data)
scaler = None
tr, ts = data2[0:int(1-len(data2)*test_size),:], data2[int(1-len(data)*test_size):,:]
xtr, xts = tr[:,:-1,np.newaxis], ts[:,:-1,np.newaxis]
ytr, yts = tr[:,-1], ts[:,-1]
for i in (xtr, xts, ytr, yts):
print(i.shape)
return (xtr, xts, ytr, yts, scaler)
def split_sequence_indicators(frame, columns, n_steps, y_true='close', test_size=0.2, scale=True):
xtrain, xtest = [], []
targ_tr, targ_ts = None, None
scalers = {}
for col in columns:
xy = split_sequence(frame[col].values, n_steps)
xtr, xts, ytr, yts, scaler = train_test(xy, test_size, scale)
scalers[col] = scaler
if all(i is None for i in [targ_tr, targ_ts]) and col == y_true:
targ_tr, targ_ts = ytr, yts
xtrain.append(xtr)
xtest.append(xts)
xtrain = np.concatenate(xtrain, axis=2)
xtest = np.concatenate(xtest, axis=2)
print()
for i in (xtrain, xtest, ytr, yts):
print(i.shape)
return (xtrain, xtest, targ_tr, targ_ts, scalers)
def normalize(data):
normalized = (data-data.mean())/data.std()
return normalized
xTrain, xTest, ytrain, ytest, scalers_ = split_sequence_indicators(serie, ['4. close', 'diff_1'], 5, y_true='4. close', test_size=0.3, scale=False)
xTrain[0], ytrain[0]
Modelado¶
LSTM¶
Como se ha mencionado anteriormente en las RNN, una de las formas más empleadas para mitigar los problemas de las RNN simples es usar arquitecturas LSTM. Básicamente, son RNN capaces de aprender dependencias a largo plazo. Esto nos permite trabajar con secuencias más largas. Para lograrlo, las celdas LSTM poseen tres unidades internas:
- Unidad de mantenimiento
- Unidad de actualización
- Unidad de output
Estas puertas permiten a la celda analizar el input y determinar a lo largo de la secuencia qué es importante, y por tanto mantenerlo y qué no lo es, y por tanto desecharlo.
El modelo que mejores resultados ha obtenido es el modelo base_lstm_model.
Arquitectura¶
- Input: recibe un input de dimensión (batch, timesteps, features), es decir, un input multivariable que consta del valor de cierre a nivel día ("close") y de la diferenciación de grado 1 ("diff_1") como segunda variable. La ventana elegida para el modelo es de 5 timesteps. Dado un batch de 32, una ventana de 5 steps y 2 features, la entrada del modelo tendría las siguientes dimensiones: (32, 5, 2).
- 3 combinaciones de:
- BatchNormalization: permite normalizar la salida de cada capa de la red para manetener una distribución constante antes de alimentar la siguiente capa.
- Una celda LSTM de 50 unidades con regularización L2 de 0.001
- Dropout: permite reducir el sobre ajuste del modelo "apagando" conexiones entre capas con una probabilidad dada
- Output:
- Una capa densa de 1 unidad que mapea la predicción del valor del día siguiente con función de activación lineal y regularización L2 de 0.002
A continuación definimos las dos últimas dimensiones del input:
n_features = 1 if len(xTrain.shape) < 3 else xTrain.shape[2]
time_steps = xTrain.shape[1]
print(f'n_features: {n_features}\ntime_steps: {time_steps}')
Definición del modelo¶
def base_lstm_model():
input_ = Input((time_steps, n_features), name='Input1')
x = BatchNormalization(name='Bn1')(input_)
x = Reshape((time_steps, n_features))(x)
x = LSTM(50, return_sequences=True, name='Lstm1', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn2')(x)
x = Dropout(0.2, name='Dp1')(x)
x = LSTM(50, return_sequences=True, name='Lstm2', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn3')(x)
x = Dropout(0.2, name='Dp2')(x)
x = LSTM(50, name='Lstm3', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn4')(x)
x = Dropout(0.2, name='Dp3')(x)
out = Dense(1, activation='linear', name='Output', kernel_regularizer=regularizers.l2(0.002))(x)
model = Model(inputs=input_, outputs=out, name='Regressor1')
return model
def lstm_model():
input_ = Input((time_steps, n_features), name='Input1')
x = BatchNormalization(name='Bn1')(input_)
x = Reshape((time_steps, n_features))(x)
x = LSTM(100, return_sequences=True, name='Lstm1', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn2')(x)
x = Dropout(0.2, name='Dp1')(x)
x = LSTM(100, return_sequences=True, name='Lstm2', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn3')(x)
x = Dropout(0.2, name='Dp2')(x)
x = LSTM(64, return_sequences=True, name='Lstm3', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn4')(x)
x = Dropout(0.2, name='Dp3')(x)
x = LSTM(50, name='Lstm4', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn5')(x)
x = Dropout(0.2, name='Dp4')(x)
out = Dense(1, activation='linear', name='Output', kernel_regularizer=regularizers.l2(0.002))(x)
model = Model(inputs=input_, outputs=out, name='Regressor1')
return model
def cnnlstm_model():
input_ = Input((time_steps, n_features), name='Input1')
x = BatchNormalization(name='Bn1')(input_)
x = Reshape((time_steps, n_features))(x)
x = Conv1D(filters=128, kernel_size=3, activation='relu', name='Conv1')(x)
x = MaxPooling1D(pool_size=2, strides=None, padding='same', name='MaxPool1')(x)
x = BatchNormalization(name='Bn2')(x)
x = Dropout(0.2, name='Dp1')(x)
x = LSTM(100, return_sequences=True, name='Lstm1')(x)
x = BatchNormalization(name='Bn3')(x)
x = Dropout(0.2, name='Dp2')(x)
x = LSTM(100, return_sequences=True, name='Lstm2', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn4')(x)
x = Dropout(0.2, name='Dp3')(x)
x = LSTM(50, name='Lstm3', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn5')(x)
x = Dropout(0.2, name='Dp4')(x)
out = Dense(1, activation='linear', name='Output', kernel_regularizer=regularizers.l2(0.002))(x)
model = Model(inputs=input_, outputs=out, name='Regressor1')
return model
def cnnGru_model():
input_ = Input((time_steps, n_features), name='Input1')
x = BatchNormalization(name='Bn1')(input_)
x = Reshape((time_steps, n_features))(x)
x = Conv1D(filters=128, kernel_size=3, activation='relu', name='Conv1')(x)
x = MaxPooling1D(pool_size=2, strides=None, padding='same', name='MaxPool1')(x)
x = BatchNormalization(name='Bn2')(x)
x = Dropout(0.5, name='Dp1')(x)
x = GRU(100, return_sequences=True, name='Lstm1')(x)
x = BatchNormalization(name='Bn3')(x)
x = Dropout(0.5, name='Dp2')(x)
x = GRU(100, return_sequences=True, name='Lstm2', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn4')(x)
x = Dropout(0.2, name='Dp3')(x)
x = GRU(50, name='Lstm3', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn5')(x)
x = Dropout(0.2, name='Dp4')(x)
out = Dense(1, activation='linear', name='Output')(x)
model = Model(inputs=input_, outputs=out, name='Regressor1')
return model
def cnn2lstm_model():
input_ = Input((time_steps, n_features), name='Input1')
x = BatchNormalization(name='Bn1')(input_)
x = Reshape((time_steps, n_features))(x)
x1 = Conv1D(filters=128, kernel_size=2, activation='relu', name='Conv1')(x)
x1 = MaxPooling1D(pool_size=2, strides=None, padding='valid', name='MaxPool1')(x1)
x1 = BatchNormalization(name='Bn2')(x1)
x1 = Dropout(0.2, name='Dp1')(x1)
x2 = Conv1D(filters=128, kernel_size=3, activation='relu', name='Conv2')(x)
x2 = MaxPooling1D(pool_size=2, strides=None, padding='same', name='MaxPool2')(x2)
x2 = BatchNormalization(name='Bn22')(x2)
x2 = Dropout(0.2, name='Dp11')(x2)
concat = Multiply(name='concat')([x1, x2])
x = LSTM(100, return_sequences=True, name='Lstm1')(concat)
x = BatchNormalization(name='Bn3')(x)
x = Dropout(0.2, name='Dp2')(x)
x = LSTM(100, return_sequences=True, name='Lstm2', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn4')(x)
x = Dropout(0.2, name='Dp3')(x)
x = LSTM(50, name='Lstm3', kernel_regularizer=regularizers.l2(0.001))(x)
x = BatchNormalization(name='Bn5')(x)
x = Dropout(0.2, name='Dp4')(x)
out = Dense(1, activation='linear', name='Output', kernel_regularizer=regularizers.l2(0.002))(x)
model = Model(inputs=input_, outputs=out, name='Regressor1')
return model
model = base_lstm_model()
model.summary()
mod_version = '0.8'
model_name = f'lstm_model_{symbol}_v{mod_version}'
model_name
#save_keras_model(export_path='.', model=model, model_name=model_name)
def train_network(model, inputs, outputs, params):
history = model.fit(inputs,
outputs,
epochs=params['epochs'],
batch_size=params['batch_size'],
shuffle=True,
validation_split=0.2,
callbacks=params['callbacks']
)
return history
def mape(y_true, y_pred):
diff = K.abs((y_true - y_pred) / K.clip(K.abs(y_true),
K.epsilon(),
None))
return 100. * K.mean(diff, axis=-1)
np.random.seed(42)
model.compile(optimizer='adam',
loss='mse', #mean_absolute_percentage_error,
#loss_weights = losses_weights,
metrics=[mape, 'mae']
)
train_params = {'epochs': 50,
'batch_size': 32,
'callbacks': [EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10),
ModelCheckpoint(model_name+'.h5', monitor='val_loss', mode='min', verbose=1, save_best_only=True)]
}
Entrenamiento¶
Entrenamos el modelo por 50 épocas alimentándolo con batches de 32 secuencias.
#hist = train_network(model, xTrain, ytrain, train_params)
lossNames = ["loss"]
plt.style.use("ggplot")
(fig, ax) = plt.subplots(len(lossNames), 1, figsize=(8, 8))
for (i, l) in enumerate(lossNames):
metric_ = hist.history
title = "Loss for {}".format(l) if l != "loss" else "Total loss"
if len(lossNames) == 1:
ax_ = ax
else:
ax_ = ax[i]
ax_.set_title(title)
ax_.set_xlabel("Epoch #")
ax_.set_ylabel("Loss")
ax_.plot(np.arange(0, len(metric_[l])), metric_[l], label=l)
ax_.plot(np.arange(0, len(metric_[l])), metric_["val_" + l], label="val_" + l)
ax_.legend()
plt.plot()
plt.tight_layout()

metricNames = ["mape", "mean_absolute_error"]
plt.style.use("ggplot")
(fig, ax) = plt.subplots(len(metricNames), 1, figsize=(8, 8))
for (i, l) in enumerate(metricNames):
metric_ = hist.history
if len(metricNames) == 1:
ax_ = ax
else:
ax_ = ax[i]
ax_.set_title("{}".format(l))
ax_.set_xlabel("Epoch #")
ax_.set_ylabel("Accuracy")
ax_.plot(np.arange(0, len(metric_[l])), metric_[l], label=l)
ax_.plot(np.arange(0, len(metric_[l])), metric_["val_" + l], label="val_" + l)
ax_.legend()
plt.plot()
plt.tight_layout()

Carga del modelo entrenado¶
Cargamos el modelo por nombre, y cargamos los pesos ya entrenados.
loaded_reg = load_keras_model(model_name)
loaded_reg.summary()
loaded_reg.load_weights('./'+model_name+'.h5')
Predicción¶
Las predicciones del modelo serán entonces:
- Dado una ventana de 5 días de precios y sus diferenciales de grado 1, obtener el valor del día siguiente. Obtendremos para cada cada secuencia de Test, la predicción del siguiente día y al almacenaremos los resultados.
- Una vez tenidos los resultados del modelo, calcularemos las métricas de error para evaluar su ajuste.
- Por último, graficaremos tanto los puntos de predicción como los valores reales para ver cómo se se comporta la red con valores que no han sido vistos antes y cómo se ajusta al patrón de la serie.
n_features
to_pred = xTest.reshape(xTest.shape[0], time_steps, n_features)
yhat = loaded_reg.predict(to_pred, verbose=0).reshape((-1,1))
trues = ytest.reshape(-1,1)
yhat.shape, trues.shape
yhat[:5], trues[:5]
Métricas¶
def mape(y_true, y_pred):
y_true_, y_pred_ = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true_ - y_pred_) / y_true_)) * 100
prd, ytr = np.squeeze(yhat), np.squeeze(trues)
mse = sk_mse(ytr, prd)
rmse = np.sqrt(sk_mse(ytr, prd))
mae = sk_mae(ytr, prd)
mape = mape(ytr, prd)
metrics_ = pd.DataFrame([mse,rmse,mae,mape], index=['mse','rmse','mae','mape'], columns=['Metrics'])
metrics_.loc['mape'] = metrics_.loc['mape'].map(lambda x: str(round(x, 2))+'%')
metrics_
Visualización de la predicción¶
Podemos ver que el modelo aprende el patrón que sigue la serie real, excepto en algunmos tramos donde ocurren valores anómalos (picos). Pero a grandes rasgos, consigue detectar cuándo la serie tiende a subir o a bajar su valor.
plt.plot(yhat, c='seagreen', alpha=0.6)
plt.plot(trues, c='orange', alpha=0.5)
plt.legend(['prediction', 'real'], loc='best')
plt.title(model_name)

Visualicemos tramos más precisos
plt.plot(yhat[50:150], c='seagreen', alpha=0.6)
plt.plot(trues[50:150], c='orange', alpha=0.5)
plt.legend(['prediction', 'real'], loc='best')
plt.title(model_name)

plt.plot(yhat[250:350], c='seagreen', alpha=0.6)
plt.plot(trues[250:350], c='orange', alpha=0.5)
plt.legend(['prediction', 'real'], loc='best')
plt.title(model_name)

Resultados finales y Conclusiones¶
Después de estudiar los diferentes modelos de aprendizaje automático para realizar predicciones de mercado, vemos que esos cambios bruscos en los precios son difíciles de aprender para cualquiera de los modelos presentados, debido a que estas fluctuaciones de precio se pueden deber a factores externos, políticos y sociales. Los resultados son los siguientes:
Modelos
ARIMA => MSE: 0.36; RMSE: 0.63
NAÏVE DAILY => MSE: 0.46; RMSE: 0.68
RF EST. => MSE: 0.45; RMSE: 0.67
Simple RNN => MSE: 26.9; RMSE: 5.18
LTSM => MSE: 1.85; RMSE: 1.36
Los modelos tradicionales de referencia, como arrojan los resultados presentados no arrojan malos resultados en predicciones a 1 día.
De las redes secuenciales estudiadas aquí se comporta mejor las redes con capas LSTM. La posible diferencia, a peor, entre los modelos no secuenciales y los secuenciales puede venir porque estos no se adecuan tan bien a los cambios bruscos, y que los modelos simples que tienen principalmente en cuenta los últimos días son capaces de adaptarse mejor a estas series temporales tan parecidas a un Random Walk.
Es difícil predecir los precios de mercado a largo plazo, para cualquiera de los modelos sin tener en cuenta los factores externos que afectan a la economía mundial y por ende a las empresas en particular.



Comentar