
Estudio sobre redes GAN
Generación automática de imágenes de edificios (REDES GAN)¶
Inicio - Redes GAN¶
Las Redes Generativas Antagónicas, o Generative Adversarial Networks en inglés (GAN), son una potente y novedosa clase de redes neuronales. De hecho, se podría decir que se han convertido en uno de los pilares del reciente “boom” de la llamada Inteligencia Artificial. Fueron presentadas por Ian Goodfellow en 2014 y desde entonces han permitido un gran avance en el campo del aprendizaje máquina no supervisado.
Las redes GAN (Generative Adversarial Networks (GANs) son arquitecturas de redes neuronales profundas que se componen de dos redes, que se enfrentan entre sí (por lo tanto, la "confrontación - Adversial").
El funcionamiento de estas dos redes es el siguiente: una red neuronal, llamada generador, genera nuevas instancias de datos, mientras que la otra, el discriminador, las evalúa para determinar su autenticidad; es decir, el discriminador decide si cada instancia de los datos que revisa pertenece o no al conjunto de datos de entrenamiento real. (Estas dos redes, generador y discriminador la podemos ver creadas en métodos más abajo.). Estas redes GAN pueden conseguir resultados tan asombrosos como estos:
 </br></br>
</br></br>
En este cuaderno en concreto vamos a utilizar una extensión de la redes GAN, las llamadas Conditional GAN. CGAN es un tipo de red en el que se aplica una configuración condicional, lo que significa que tanto el generador como el discriminador están condicionados a algún tipo de información auxiliar, como etiquetas de clase o datos de otras modalidades. En este caso convertimos fachadas de edificios en edificios reales.
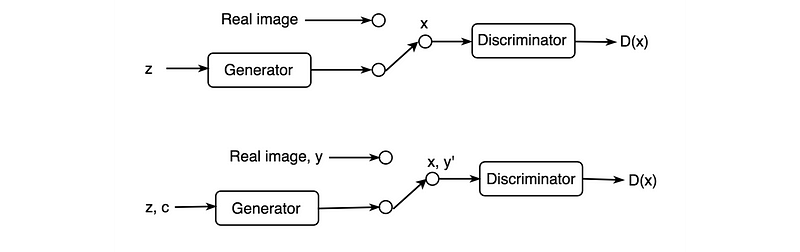
En CGAN, las etiquetas actúan como una extensión del espacio latente z para generar y discriminar mejor las imágenes. La parte superior de la figura a continuación es la GAN regular y la parte inferior agrega etiquetas al generador y al discriminador para capacitar mejor a ambas redes (CGAN).
 </br></br>
</br></br>
¿Pero que significa esto exactamente? En GAN, no hay control sobre los modos de los datos que se generarán. El GAN condicional cambia eso al agregar la etiqueta y un parámetro adicional al generador y espera que se generen las imágenes correspondientes. También agregamos las etiquetas a la entrada del discriminador para distinguir mejor las imágenes reales.
En nuestro caso nuestra etiquetas condicionales serán las estructuras de los edificios que podemos ver en la primera de las 3 siguientes imágenes. En el ejemplo, usaremos la base de datos de fachada de CMP. A nivel de computación podremos ver que es costoso: cada época toma alrededor de 58 segundos en una sola GPU P100. Pero los resultados son realmente sorprendentes, en la siguiente imagen podemos ver salida generada después de entrenar el modelo para 200 épocas.
</br></br>
Conocer el dataset¶
Empezaremos primero con los import que en este caso vamos a utilizar tensor flow sin un framework por encima.
Respecto al dataset lo podemos encontrar aquí es un dataset provisto por el "Center for Machine Perception"en Czech Technical University, Praga.
Para tratar las imágenes aplicamos jittering aleatorio (En este caso se tratará de cortar aleatoriamente y mover o reflejar la imagen) y reflejo al conjunto de datos de entrenamiento.
from __future__ import absolute_import, division, print_function, unicode_literals
!pip install tensorflow-gpu==2.0.0-beta1
import tensorflow as tf
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
_URL = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'
path_to_zip = tf.keras.utils.get_file('facades.tar.gz',
origin=_URL,
extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'facades/')
Definimos el tamaño del buffer, batch size y tamaño de imágenes. Debemos tener en cuenta que parámetros como el batch size es crítico ya que esta serie de GAN son bastante costosas a nivel computacional y tenemos que elegir muy bien entre capacidad de nuestros entornos y requerimientos.
BUFFER_SIZE = 400
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
Función de carga de imágenes, convierte y normaliza la imagen de entrada.
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
w = tf.shape(image)[1]
w = w // 2
real_image = image[:, :w, :]
input_image = image[:, w:, :]
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Ahora veamos algunos tipos de imágenes que nos proporciona el dataset, la primera será imagen condicional y la segunda la imagen real.
inp, re = load(PATH+'train/100.jpg')
# casting to int for matplotlib to show the image
plt.figure()
plt.imshow(inp/255.0)
plt.figure()
plt.imshow(re/255.0)


Definimos ahora algunas funciones para el procesamiento de las imágenes:
- Resize
- Recorte aleatorio
- Normalizar
- Jitter aleatorio (mover y recortar aleatoriamente la imagen.) En otros casos el jitterin puede consistir en reemplazar cada pixel por uno del grupo perteneciente, pero para este caso simplement vamos a cambiar aleatoriamente la imagen.
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# resizing to 286 x 286 x 3
input_image, real_image = resize(input_image, real_image, 286, 286)
# randomly cropping to 256 x 256 x 3
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Veamos la prueba de alguna de estas funciones.
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i+1)
plt.imshow(rj_inp/255.0)
plt.axis('off')
plt.show()

Funciones de carga del dataset.
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Carga del dataset en Train - Test¶
Cargamos el dataset y lo definimos en train / test. Se hará un suffle en test para cada epoch, así se generará una imagen diferente para predecir y mostrar el progreso de nuestro modelo.
train_dataset = tf.data.Dataset.list_files(PATH+'train/*.jpg')
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.batch(1)
test_dataset = tf.data.Dataset.list_files(PATH+'test/*.jpg')
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(1)
Build the Generator¶
Empezamos ahora con el generador, el encargado de crear la imagen predicha. La arquitectura del generador es una U-Net modificada:
- Cada bloque en el encoder es (Conv2D -> Batchnorm -> Leaky ReLU)
- Cada bloque en el decoder es (Transposed Conv -> Batchnorm -> Dropout (aplicado a los primeros 3 bloques) -> ReLU)
Encoder:¶
Conv2D -> BatchNormalization -> Leaky ReLU
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
Decoder¶
Conv2DTranspose -> BatchNormalization -> Dropout (aplicado a los primeros 3 bloques) -> ReLU
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
Creamos ahora la definición del generador, esta es relativamente compleja y es mejor basarse en modelos ya existentes.
def Generator():
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
concat = tf.keras.layers.Concatenate()
inputs = tf.keras.layers.Input(shape=[None,None,3])
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = concat([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Probemos ahora a ver una imagen de ejemplo generada. Como podemos observar la predicción no es nada buena, pero no esta del todo alejada de la imagen condicional que antes hemos podido ver. Para poder afinar esto debemos crear el discriminador.
generator = Generator()
gen_output = generator(inp[tf.newaxis,...], training=False)
plt.imshow(gen_output[0,...])

Discriminator¶
El discriminador es un PatchGAN.
- Cada bloque en el discriminador es (Conv -> BatchNorm -> Leaky ReLU)
- Cada parche de 30x30 de la salida clasifica una porción de 70x70 de la imagen de entrada (tal arquitectura se llama PatchGAN).
El discriminador recibe 2 entradas.
- Imagen de entrada y la imagen de destino, que debe clasificarse como real.
- Imagen de entrada y la imagen generada (salida del generador), que se debe clasificar como falsa.
- Concatenamos estas 2 entradas.
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[None, None, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[None, None, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Veamos ahora el mapa de calor de lo buena que es la imagen predicha.
discriminator = Discriminator()
disc_out = discriminator([inp[tf.newaxis,...], gen_output], training=False)
plt.imshow(disc_out[0,...,-1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()

Loss functions y optimizers¶
Esta es una de las partes más importantes ya que estos parámetros serán los únicos que compartirán nuestro generador y discriminador, el éxito de nuestra red se definirá por estos. La explicación exacta de los parámetros y arquitecturas de esta red la podemos encontrar en este paper
Discriminator loss
- La función de perdida del discriminador toma dos entradas, la imagen real y la generada. A la imagen real se le aplicará una real_loss (sigmoid cross entropy loss) y la imagen generada se aplicará una generated_loss (sigmoid cross entropy). La loss_total será la suma de ambas.
Generator loss
- Es una sigmoid cross entropy loss de las imágenes generadas y array de estas.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Como es computacionalmente costoso, establechemos unos checkpoints para ir guardando poco a poco las imágenes.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Generar imágenes¶
Después del entrenamiento, es hora de generar algunas imágenes! (Imágenes de prueba -> generador -> Traducir -> predicción)
EPOCHS = 150
def generate_images(model, test_input, tar):
# the training=True is intentional here since
# we want the batch statistics while running the model
# on the test dataset. If we use training=False, we will get
# the accumulated statistics learned from the training dataset
# (which we don't want)
prediction = model(test_input, training=True)
plt.figure(figsize=(15,15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
@tf.function
def train_step(input_image, target):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
Training¶
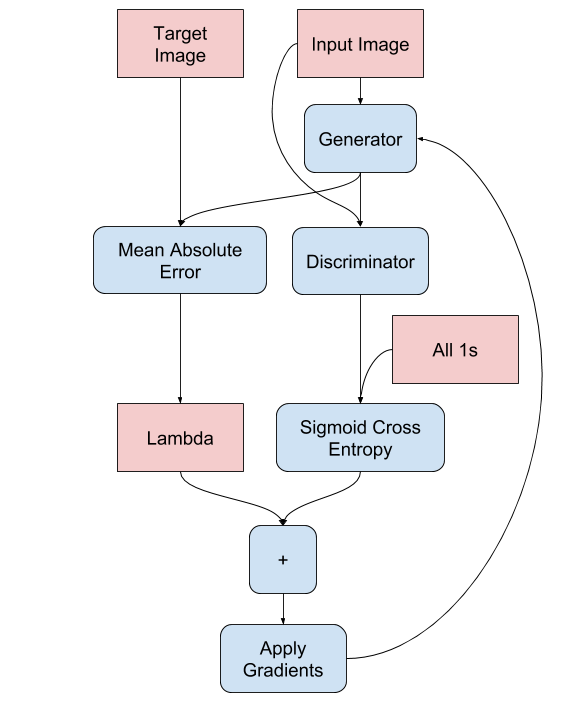
Comenzamos por iterar sobre el conjunto de datos.
El generador obtiene la imagen de entrada y obtenemos una salida generada.
El discriminador recibe la input_image y la imagen generada como la primera entrada. La segunda entrada es input_image y target_image.
A continuación, calculamos el generador y la pérdida del discriminador.
Luego, calculamos los gradientes de pérdida con respecto tanto al generador como a las variables discriminadoras (entradas) y las aplicamos al optimizador.
Podemos ver el proceso en la siguiente imagen:
 </br></br>
</br></br>
El proceso de entrenamiento será realmente costoso, es recomendable el uso de una GPU por ejemplo para acelerarlo.
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for input_image, target in dataset:
train_step(input_image, target)
clear_output(wait=True)
for inp, tar in test_dataset.take(1):
generate_images(generator, inp, tar)
# saving (checkpoint) the model every 20 epochs
if (epoch + 1) % 20 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))
train(train_dataset, EPOCHS)
Ver resultados¶
Bien ahora que ya tenemos el modelo entrenado es momento de generar algunas imágenes, podemos ver que según cuanto hemos entrenado el modelo la imagen generada se parecerá más o menos a nuestra imagen real. Igualmente se puede ver que con pocos intentos los resultados son prometedores.
!ls {checkpoint_dir}
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
# Run the trained model on the entire test dataset
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)





Referencias
1.- Las explicaciones y código se han obtenido de Pix2Pix



Comentar