
Peritaje automático de vehículos con Redes Convolucionales (Mask R-CNN)
Una red neuronal convolucional (Convolutional Neural Networks en inglés, con los acrónimos CNNs o ConvNets) es un caso concreto de redes neuronales Deep Learning, estas han tenido un auge exponencial recientemente dado sus excelentes resultados, pero ya se conocen desde los años 90.
Para hacernos una idea intuitiva de cómo funcionan estas redes neuronales, pensemos en cómo nosotros reconocemos las cosas. Por ejemplo, si vemos una cara, la reconocemos porque tiene orejas, ojos, una nariz, cabello, etc. Entonces vamos asimilando en nuestra cabeza qué rasgos cumple y asignamos una probabilidad de que sea una cara. Por ejemplo, si vemos una posible cara de noche, pero la mitad de ella esta oscura puede que dudemos al decidir mentalmente si se trata de una persona o no, dado que no vemos claramente los rasgos suficientes de una cara. Las redes convolucionales hacen algo similar, dar una posibilidad de que el objeto que buscamos sea el que ve en la imagen.
Inicio - Mask R-CNN¶
El objetivo de este post es construir un modelo CNN con máscaras de región (Mask R-CNN) que pueda detectar el área de daño en un automóvil. El problema de una red CNN es que puede encontrar miles de objetos y regiones, para paliar este problema se crearon las R-CNN. En R-CNN, la CNN está obligada a enfocarse en una sola región, porque de esa manera se minimiza la interferencia de otros objetos. Las regiones en el R-CNN se detectan mediante un algoritmo de búsqueda selectiva seguido de cambio de tamaño, de modo que las regiones tengan el mismo tamaño antes de que se envíen a un CNN para la clasificación y la regresión del cuadro delimitador. Es decir, una R-CNN busca en n-regiones y se enfoca en encontrar el objeto-target, de ahí que nos sirva de manera idónea para este caso. Por ejemplo, los primeros casos de uso de estas redes R-CNN son en la conducción autónoma, ya que sirven de manera espectacular para la detección de coches en una carretera; procesará diferentes regiones en busca de los n-coches de la imagen.

Inicio - Cómo crear una R-CNN¶
Una buena forma de imaginar una R-CNN es por medio de la combinación de una faster-R-CNN y una Fully Conected CNN. La primera Faster R-CNN, buscará las región en la cual cree que esta el objeto, y la clase de estas, la Fully conected CNN, encontrará el objeto en esa región.
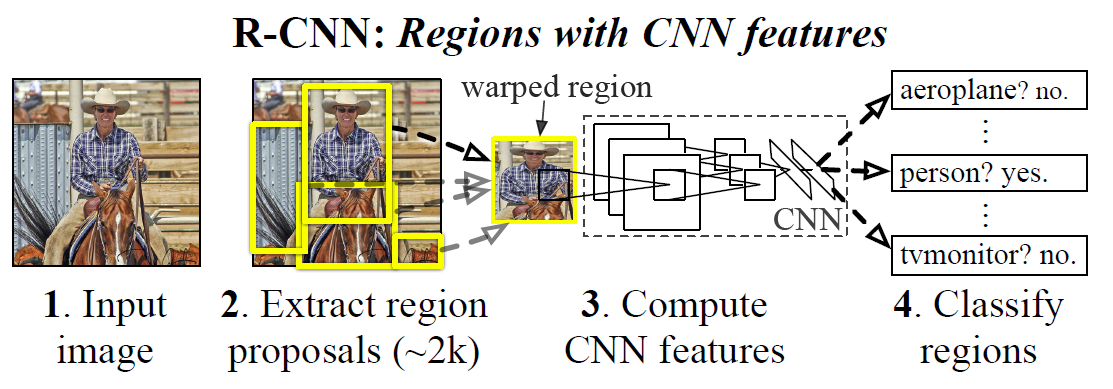
En el siguiente ejemplo, podemos ver claramente como en el primero paso, la Faster R-CNN nos devuelve la región en la que se encuentra el jugador principal, con su respectiva etiqueta de clasificación, y en el siguiente paso la Fully Conected CNN encontrará este objeto.

Para crear una máscara R-CNN personalizada, aprovecharemos el repositorio Matterport Github. El último repositorio de TensorFlow Object Detection también ofrece la opción de crear Mask R-CNN, pero se recomienda utilizar esta librería ya que sino te encontrarás con muchos problemas que alguién ya se revolvió en resolver.
Recopilación del Data-set¶
Se utilizarán 60 imágenes de coches dañados obtenidos de google. Estas imágenes se necesita que tengan el área del daño perimetrada, para ello se creará un Dataset con estos datos ya específicados.

</br></br>
Train del modelo¶
Primero traemos las librerías necesarias para entrenar este modelo antes citadas y definimos también los directorios de los pesos ya entrenamos de COCO. Esta es un dataset de todo tipo de imágenes las cuales han sido entrenadas, y tenemos los pesos de ese entrenamiento. Esto nos servirá de punto de partida para entrenar el modelo usando el transfer learning.
import os
import sys
import json
import datetime
import numpy as np
import skimage.draw
import cv2
from mrcnn.visualize import display_instances
import matplotlib.pyplot as plt
from mrcnn.config import Config
from mrcnn import model as modellib, utils
# Path to trained weights file
COCO_WEIGHTS_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
En la siguiente función importaremos el dataset. Se trabaja con la búsqueda del objeto "damage", para ello se añaden cierta metadata a cada imagen para que luego la librería pueda trabajar con ella. Es el caso, de esta clase damage, o los atributos de Width y height del shape.
def load_custom(self, dataset_dir, subset):
# Add classes. We have only one class to add.
self.add_class("damage", 1, "damage")
# Train or validation dataset?
assert subset in ["train", "val"]
dataset_dir = os.path.join(dataset_dir, subset)
# We mostly care about the x and y coordinates of each region
annotations1 = json.load(open(os.path.join(dataset_dir, "via_region_data.json")))
# print(annotations1)
annotations = list(annotations1.values()) # don't need the dict keys
annotations = [a for a in annotations if a['regions']]
# Add images
for a in annotations:
polygons = [r['shape_attributes'] for r in a['regions'].values()]
image_path = os.path.join(dataset_dir, a['filename'])
image = skimage.io.imread(image_path)
height, width = image.shape[:2]
self.add_image(
"damage", ## for a single class just add the name here
image_id=a['filename'], # use file name as a unique image id
path=image_path,
width=width, height=height,
polygons=polygons)
Función de creación de una máscara pasada una imagen, creará una máscara con las características de alto x ancho que le pasemos, lo devolverá en el formato adecuado.
def load_mask(self, image_id):
image_info = self.image_info[image_id]
if image_info["source"] != "damage":
return super(self.__class__, self).load_mask(image_id)
info = self.image_info[image_id]
mask = np.zeros([info["height"], info["width"], len(info["polygons"])],
dtype=np.uint8)
for i, p in enumerate(info["polygons"]):
# Get indexes of pixels inside the polygon and set them to 1
rr, cc = skimage.draw.polygon(p['all_points_y'], p['all_points_x'])
mask[rr, cc, i] = 1
return mask.astype(np.bool), np.ones([mask.shape[-1]], dtype=np.int32)
Para la posterior visualización del los objetos detectados crearemos una función que se encargará de pintar la región que ha encontrado en la imagen en cuestión.
def color_splash(image, mask):
gray = skimage.color.gray2rgb(skimage.color.rgb2gray(image)) * 255
# We're treating all instances as one, so collapse the mask into one layer
mask = (np.sum(mask, -1, keepdims=True) >= 1)
if mask.shape[0] > 0:
splash = np.where(mask, image, gray).astype(np.uint8)
else:
splash = gray
return splash
Este será la función train del modelo, como ya viene pre-entrenada con los pesos de COCO no será necesario entrenarla mucho, lo haremos sólo con 10 veces.
def train(model):
# Training dataset.
dataset_train = CustomDataset()
dataset_train.load_custom(args.dataset, "train")
dataset_train.prepare()
# Validation dataset
dataset_val = CustomDataset()
dataset_val.load_custom(args.dataset, "val")
dataset_val.prepare()
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=10,
layers='heads')
Train principal¶
- Crearemos primero un modelo de MaskRCNN provisto por la librería de Matterport.
- En este caso cargaremos los pesos pre-entrenados de la librería de COCO.
- Primero entrenaremos el modelo
- A posteriori podemos pasarle una imagen y ver el resultado con la función de detect_and_color_splash
# Create model
if args.command == "train":
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=args.logs)
else:
model = modellib.MaskRCNN(mode="inference", config=config,
model_dir=args.logs)
weights_path = COCO_WEIGHTS_PATH
if args.weights.lower() == "coco":
# Exclude the last layers because they require a matching
# number of classes
model.load_weights(weights_path, by_name=True, exclude=[
"mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
else:
model.load_weights(weights_path, by_name=True)
if args.command == "train":
train(model)
elif args.command == "splash":
detect_and_color_splash(model, image_path=args.image,
video_path=args.video)
Para entrenar este modelo, y hacer lo que hemos citado en los pasos anterior ejecutaremos el siguiente comando:
## Train a new model starting from pre-trained COCO weights
python3 custom.py train --dataset=/path/to/datasetfolder --weights=coco
Al acabar podemos obtener predicciones de este tipo

Mask-RCNN es la siguiente evolución de los modelos de detección de objetos ya que permiten la detección con mejor precisión.
Referencias
1.- Las explicaciones se han obtenido de analitics vidhya
2.- El código de priya-dwivedi github



Comentar